運算新時代來臨!
隨著輝達GTC大會發表Blackwell架構、NIM微服務、Omniverse Cloud API等劃時代的AI新技術,並推出集合B200的超級晶片GB200,宣告AI算力兆級參數時代來臨。
文/周佳蓉
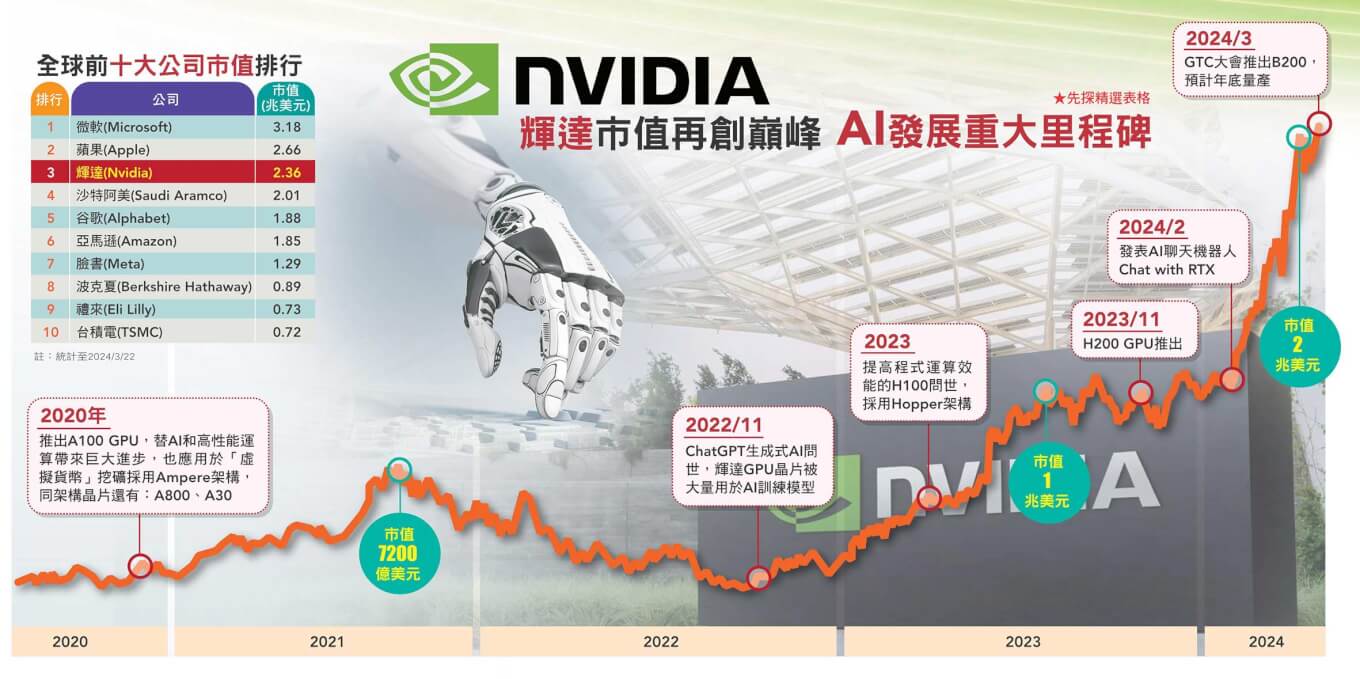
誰也不會想到,一家過去單純做圖形處理器(GPU)起家的公司,中間曾二度瀕臨倒閉困境,竟然能在三十年後,衝上全球市值第三大的巨型企業,更在AI晶片領域橫掃九成的市占率!去年七月,輝達(Nvidia)市值從一百億美元躍升一兆美元,耗時了八年,今年二月二十三日股價在盤中衝上八二三元、市值再翻倍到二兆美元,卻僅相隔不到八個月,市值暴漲的速度遠勝於蘋果(Apple)、微軟(Microsoft)。儘管身處GPU激烈競爭的紅海之中,後有追兵超微(AMD)來勢洶洶,還有谷歌、蘋果、微軟、臉書、特斯拉等科技巨頭為了降低對輝達依賴,投入客製化晶片的行列,在今年GTC大會落幕後,眾多華爾街分析師及外媒大膽斷言:「輝達短時間內難有對手有機會追趕」,究竟他是靠著什麼優勢,能穩穩站妥AI晶片霸主的地位?
短時間內難有對手
回溯輝達的發展歷程,早在二○○七年就高瞻遠矚地建立了CUDA軟體平台架構,這項創舉意味著,將複雜顯卡程式設計統一打包為簡單介面,開發人員能夠輕易執行各種應用開發,涵蓋範圍廣及科學運算、影像處理以及深度學習等領域。如今全球約有三千家AI新創公司使用CUDA平台,就如同蘋果的iOS系統一樣,為輝達築起了堅實的生態優勢,也讓在後苦追的競爭對手難以企及。
可以發現,輝達近年除了在硬體、軟體方面加足馬力,也開始嘗試往AI應用終端發展,例如今年二月推出面向一般用戶的ChatwithRTX,是能在個人電腦或工作站運行的AI聊天機器人、面向企業和新創公司也推出「AI代工服務」加速應用程式開發等,確保在高速奔跑的AI領域不錯過商機。
GTC2024堪稱五年來科技界最盛大的實體大會,現場聚集超過一萬一千名與會者,是輝達又一個高光時刻,在主題演講中,創始人兼執行長黃仁勳重磅推出了一系列AI新品和技術,包括新一代GPU、AI加速器、AI軟體開發工具等,為AI技術的發展再添注嶄新動能。
繼二○二二年的Hopper架構之後,輝達的次世代Blackwell架構於今年GTC大會正式亮相,全新的架構將搭載於B100、B200GPU之中,還有進一步由兩片B200與一顆GraceCPU組合而成AI超級晶片GB200問世,由於功耗升級且受限於散熱空間不足,輝達宣布GB200將採用液冷散熱來達到效率最佳化,GB200的液冷配置範圍為七○○∼一二○○瓦,在推理、能源效率和成本降低方面取得重大進展,會場上也見到GB200NVL72機櫃組,將最高三六顆NvidiaGraceCPU和七二塊BlackwellGPU放入機架中,GPU之間以第五代的NVLink互連,並導入Nvidia的BlueField-3資料處理單元,可於超大規模的AI雲端中實現網路加速、儲存、零信任安全,以及彈性的GPU運算能力。
Blackwell架構晶片總共包含六大重點升級,一、採用台積電先進製程(N4P)打造,GPU整合兩個獨立製造的裸晶,由二○八○億個電晶體組成,數量是前一代GPU八百億個電晶體的二倍以上;二、支援FP4精度的第二代Transformer引擎;三、雙向吞吐量達一.八T/秒的第五代NVlink技術、每個GPU提供每秒一八○○GB的頻寬,能串聯高達五七六個GPU高速傳輸;四、AI自我診斷的RSA引擎,能預判潛在故障問題、縮短停機時間;五、具備運算功能的安全AI,可在不影響性能之下保護AI模型與客戶數據;六、支援最新格式的解壓縮引擎,加快資料庫查詢速度。
AI開發軟體NIM
而DGXSuperPOD為新一代超級電腦平台,由八套或以上數量的DGXGB200系統打造而成,採用液冷設計,提供十一.五exaflops的AI運算能力,內含二八八個CPU、五七六個GPU、二四○TB的記憶體,並可透過額外的機架進行擴展,同時因應兆級參數GPU運算與AI基礎設施需求,輝達也亮相兩款新型交換機產品─Quantum-X800InfiniBand與Spectrum-X800乙太網路,提供資料中心最佳化的AI網路,最高達八○○Gb/s的端到端吞吐量,輝達的AI系統此後都可以透過InfiniBand網路連接進一步擴展,進而獲得海量算力。
NIM是輝達根據加速運算庫和生成式AI模型所推出的AI軟體包,涵蓋符合各產業標準的API,讓開發者存取AI模型並快速打造AI應用,未來開發者可能不再需要逐行編寫密集的代碼,只要與AI進行互動,就能完成訓練及應用。輝達強調:「未來的公司會將精力放在組裝AI模型,而不是編寫軟體」,此外,黃仁勳也介紹了OmniverseCloudAPI,它可以提供先進的模擬能力,將AI引入物理世界,例如蘋果頭戴裝置VisionPro、MetaQuest都將支援開發3D工作流程與應用程序,藉此推動Omniverse生態系統持續成長,其他還有Ansys、Cadence、微軟、西門子等大型工業軟體製造商已開始在採用,進行模擬分析、驗證旗下產品。
鴻海掌握垂直整合優勢
在晶片設計和製造領域,黃仁勳提到,去年GTC大會推出的cuLitho技術,原本讓五○○個H100系統可以達到四萬個CPU系統的工作量,台積電現在將cuLitho整合進工作流程中,僅需要三五○個H100系統就能達到相同工作效果,大幅提升晶圓製造/代工的效率,並為日後發展二奈米及更先進製程奠定基礎。
在AI伺服器供應鏈當中,鴻海(2317)因具備GPU模組、GPU基板、SmartNIC/DPU、散熱片、風扇、機殼、整機與系統的豐富製造經驗,垂直與水平整合優勢高,去年伺服器營收中有三○%為AI伺服器,今年AI相關訂單動能可望更強勁。
法人表示,鴻海和廣達(2382)將瓜分輝達GB200的機櫃訂單,GB200凸顯的是高效能、更多的機架以及採用液冷設計,鴻海在液冷散熱技術深耕長達五年,集團內除了能提供機櫃整體空間設計優化、運算效能提升、提高節能表現,總部設於美國的AMAX-KY(6933)為鴻海持股二五%公司,也成為液冷散熱趨勢的受惠者,其他散熱業者如奇鋐(3017)、雙鴻(3324)、尼得科超眾(6230)等皆有布局伺服器液冷散熱;另外,當AI伺服器步入數兆參數運算的時代,相對應的先進製程、封裝、記憶體等技術及產能勢必得跟上,以最新的輝達Blackwell架構中,最有感升級莫過於電晶體數量、記憶體HBM3e導入以及GPU之間傳輸互聯的NVlink技術,在後續的章節,將為投資朋友深入詳述其基礎原理和相關受惠股。
閱讀完整內容
本文摘錄自
輝達Blackwell 王者生態圈
先探投資週刊
2024/4月 第 2293期
相關