蔡炎龍 政治大學應用數學系副教授,專長為代數幾何及深度學習。近年來致力推廣Python程式語言及人工智慧教學。
Take Home Message
• 深度學習的概念為將實務問題轉化成函數,再用神經網路打造出函數學習機,並學會此函數。
• ChatGPT 等文字生成AI 的設計原理為輸入前一個字之後,AI 會預測下一個字,再將預測的字加入指令(prompt)、再預測下一個字,藉此生成文章。
• Midjourney 等圖像生成AI 的原理則應用了「自編碼器」:輸入一張圖,經過神經網路一層層的編碼、解碼之後再將圖像輸出。
這幾個月以來,美國研究型非營利公司OpenAI 開發的文字生成式AI(generative artificial intelligence, GAI)ChatGPT 以及各種圖像生成AI,例如Stable Diffusion、Midjourney 等都廣受歡迎,生成式AI也成了非常熱門的主題。大家最近可能也常聽到一個名詞——AIGC(AI generated content),顧名思義就是由AI 生成的內容,無論是文字、影像或音樂等內容皆透過生成式AI 產出。
以簡單的例子比喻,生成式AI就是讓電腦「創作」。雖然這件事聽起來有點神奇,但其實原理可能比想像中簡單。在開始說明生成式AI 的原理之前,先來談談到底如何讓電腦生成文字、圖像,或是任何一種創作。
讓電腦知道該學什麼
首先,我們需要回顧一下深度學習(deep learning)的基本精神。深度學習只能做到一件事情:把實務的問題化成一個函數,然後用神經網路(neural network)技術打造一個函數學習機,並學習這個問題化成的函數。
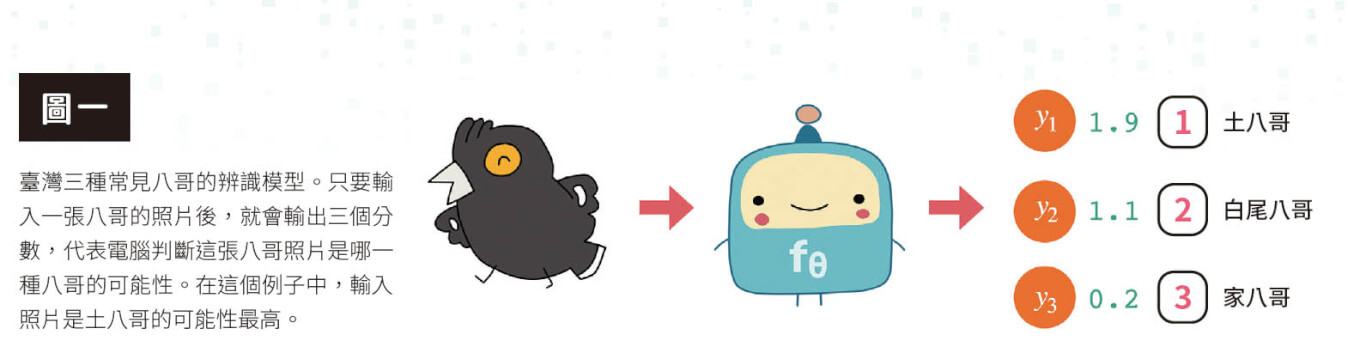
我們以製作「八哥」的辨識模型為例。如果想要打造一個能辨識出臺灣三種常見八哥——原生種八哥(Acridotheres cristatellus,俗稱土八哥)、外來種白尾八哥(Acridotheres javanicus)、外來種家八哥(Acridotheres tristis)的模型,我們可以設計一個函數,在輸入一張八哥的照片後,函數會輸出三個分數,分別代表電腦判斷這張八哥照片是哪一種八哥的可能性,如果土八哥的得分最高,那麼AI 模型就會判斷這張圖片中的鳥是土八哥(圖一)。還可以使用softmax 函數讓三個分數加起來等於1,例如讓函數輸出這張圖片為「土八哥的機率是15%、白尾八哥的機率是25%、家八哥的機率是60%」。
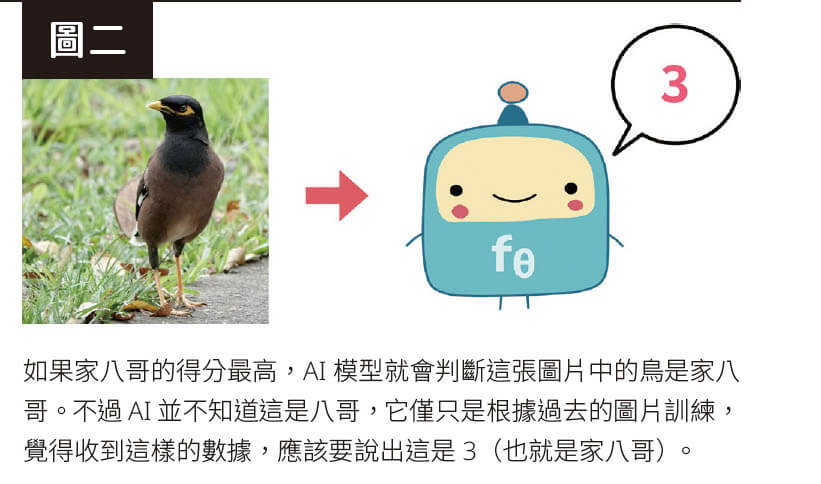
不過在使用這類模型時有件事一定要注意,那就是AI 其實並不知道這是八哥!它甚至不知道這是一隻鳥。我們輸入的照片對AI 而言只是一筆數據,它僅是根據過去的訓練,認為收到這樣的數據後,應該要輸出這是得分最高的土八哥(圖二)。後面會講到的ChatGPT 也是同樣的模式,它只是根據學習的經驗,覺得應該輸出第87 號或第52 號字等。
文字生成的AI
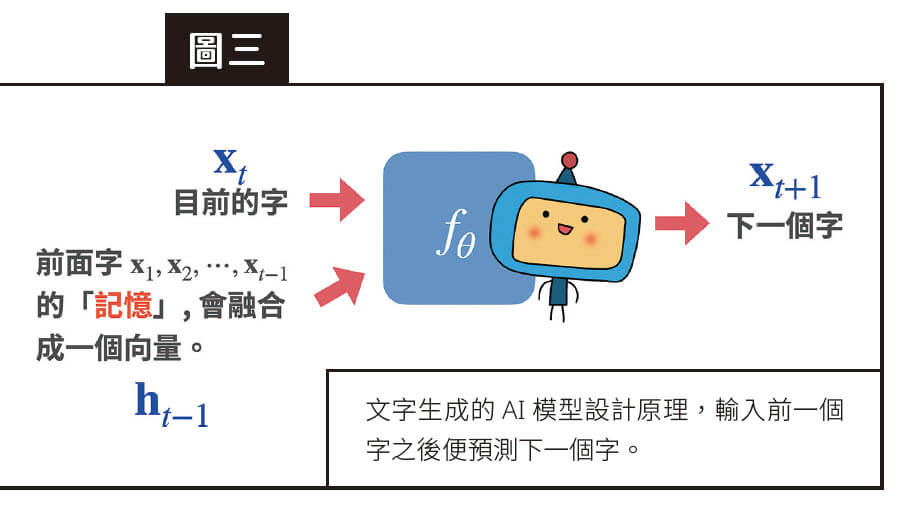
深度學習基本上就是個函數,最重要的是知道輸入了什麼(如八哥的照片)、輸出的是什麼(如代表數據類型的三個數字)。那文字生成的AI 模型該怎麼設計呢?答案可能是出乎意料的簡單——只要輸入前一個字,就預測下一個字!
文字生成模型的作用方式就是當你輸入一段指令(prompt),也就是大家說的「咒語」,就能產生下一個字。若把這個字再加到咒語中,就會再產生下一個字。以此類推,便可以產生一段很長的文字。
不知道讀者看到這裡有沒有覺得哪裡有點奇怪,我們的模型明明只是「輸入一個字,輸出一個字」,為什麼能輸入一整段咒語呢?原來這動用了有「記憶」的神經網路模型,例如傳統使用的是循環神經網路(recurrent neural network, RNN),而現在比較流行的則是「transformers」。簡單的說,這種「輸入一個字、預測下一個字」的模型,輸入並不只是一個字,也包括前面看過字的「記憶」。於是這個模型就會看完「前面的一串字」、預測下一個字,把預測的字加入咒語、再預測下一個字。以此類推,就可以生成出長篇的文章(圖三)。
你可能會懷疑,這樣簡單的模型真的有用嗎?我們可以試著讓電腦讀完整本《紅樓夢》,然後就能輸入任意的咒語進去,最後生出一段像是《紅樓夢》風格的文字(圖四)。
這段生成出來的文字看起來好像是一篇文章,單獨的句子看起來也似乎是《紅樓夢》的風格,可是看完整個段落又會不知道在說什麼。這也引發了一個想法——會不會是訓練用的資料不夠多呢?
看得多就變厲害的ChatGPT
2019 年初,AI 文字生成出現一個重要的模型:OpenAI 推出的GPT-2。GPT-2 的代表作是OpenAI自己輸入了一段十分誇張的咒語:「一群科學家在美國安地斯山脈發現獨角獸的族群,而且這些獨角獸還會說流利的英文。」沒想到如此誇張的起頭,GPT-2 居然還接得下去,並寫出了一篇真的很像新聞的報導,文中甚至提到是什麼大學、哪位老師帶領的研究團隊,以及他們如何發現這群獨角獸。
GPT-2 讓大家知道,如果訓練的資料夠多、模型夠大,就可以讓電腦寫出很像人類撰寫的文字。GPT-2 模型中的參數總共有15 億個,相較於當時較有名的語言模型,像是ELMo(Embeddings from Language Models)、BERT(Bidirectional Encoder Representations from Transformers)等,都龐大了許多。若是和上述只有300 萬個參數的「紅樓夢生成器」比起來,更是大到可怕!
OpenAI 並沒有停在這裡,後來的ChatGPT 所使用的GPT-3.5,參數量已來到了 1750 億!這個數字是什麼樣的概念呢?意思是即使OpenAI 願意,一般人的電腦也沒辦法把這麼大的模型下載下來,更不用說執行了。
除了模型變大,另一個重點是ChatGPT「讀」了非常多的文字。若問ChatGPT「人的一生平均讀多少字」,ChatGPT 回答是 5300 萬字。而ChatGPT 則大約讀了4990 億個字,也就是說一個人大約要能活到65 萬歲才能讀這麼多字!
自編碼器
現在我們了解文字生成型的AI 如何做到文字創作了,但其他像是圖像創作、音樂創作是如何運作的呢?這類「一個字生下一個字」的模型似乎不太能運用到其他方面的創作。
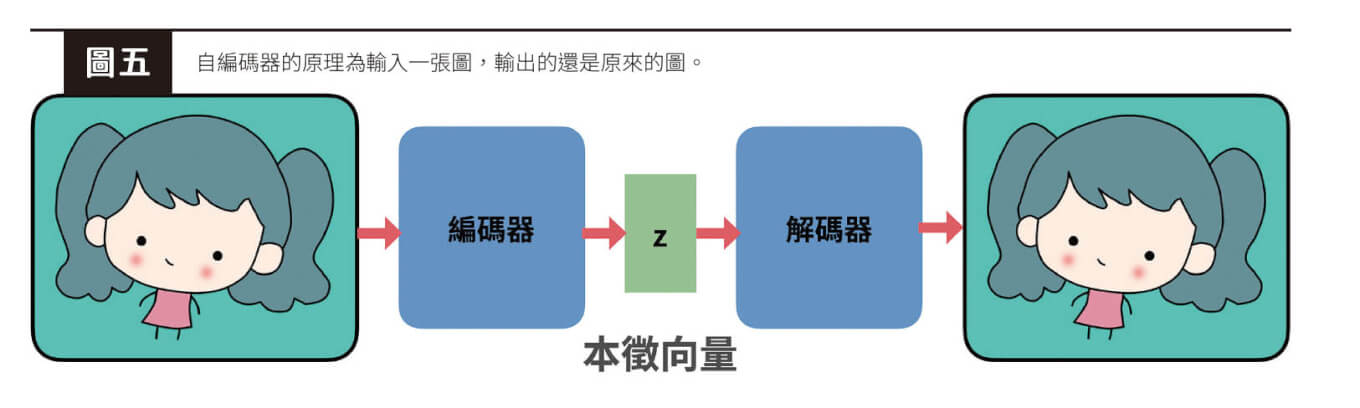
其實圖像、音樂創作類型的AI 原理意外的簡單——我們可以用「自編碼器」(autoencoder)的方式操作:此模型就是輸入一張圖,輸出還是原來的圖(圖五)。你可能會覺得困惑,這種模型有什麼用?這裡重點在於,深度學習是由一層層神經網路的方式建構。模型接收到輸入的指令之後,每一層都會輸出一組數字再傳到下一層,而每一層輸出的數字也都可以當成是神經網路對原輸入指令的「抽象理解」。將輸出文字稱為抽象理解的原因是,若把這組數字單獨拿出來看,我們沒有辦法理解這組數字代表著什麼意思。
自編碼器中間每一層的輸出都可以當成神經網路的理解,我們可以抽出任何一層的輸出,當成是原來輸入的「本徵向量」(latent vector,又稱特徵代表向量)。這個本徵向量再經過後面的運算,的確可以還原為原來的圖,因此我們可以確定它真的能掌握原本的圖。
從自編碼器到圖像創作
自編碼器在應用的時候可以分成兩個模型,前半部從輸入轉成本徵向量的部分稱為「編碼器」;而後半部從本徵向量還原成圖的則稱為「解碼器」。如果我們隨機產生不同的本徵向量,理論上就會創作出不同的圖(圖六)。
這聽起來似乎有點太過簡單,但文字生成模型給了我們很大的啟發——GPT 「讀」了大量的文字,有了令人驚豔的文字生成能力,所以或許讓模型「看」了足夠多的圖,就可以生出很棒的圖!
不過這裡還有個小問題,我們該怎麼確定什麼樣的本徵向量是合理的,應該會生出一張品質好的圖呢?一個很自然的想法是想辦法讓本徵向量的每一個數字都符合某個常態分布(normal distribution,又稱高斯分布),例如標準常態分布(standard normal distribution)。因此由這個常態分布隨機抽樣出的本徵向量,應該就能生出一張漂亮的圖。
擴散模型
怎麼做才能神奇地讓本徵向量服從某個常態分布?以下有幾種作法,讓我們理解近來大紅的擴散模型都怎麼做,包括前面提過的Midjourney、Stable Diffusion、DALL.E 等,都是使用這種方法。這類模型的原理基本上使用自編碼器,但編碼器是以標準的方式算出來,解碼器才送交給神經網路去做。
編碼的過程是一次加上一點高斯雜訊(Gaussian noise)〔註〕,所以我們也會稱為「加雜訊」的過程。經過若干步驟之後,整個編碼就會看起來像是雜訊。這時可以進一步藉由統計分析證明,每一個點都符合常態分布,也就是真的達成讓本徵向量分布呈現出某個常態分布的目標(圖七)。
註|經過統計分析後會呈現常態分布的一種雜訊。
至於擴散模型解碼器,也就是還原的步驟,常被稱作「去雜訊」。你可能會有疑問:「既然加雜訊是用標準的方法算出來,為什麼去雜訊不可以呢?」
原因大致是這樣:假設我們有一條非常完美、平滑的曲線,如果被加上一點雜訊、想要還原的時候,其實就是我們熟悉的「回歸」。若是本來就知道原本的曲線長得像什麼(比如直線),當然就可以直接算出原始的曲線;但一般而言我們不會知道,所以才需要用神經網路學習。
用深度模型讓電腦創作
生成模型讓電腦創作的魔法其實還是會回歸到深度學習的基本概念:「我們要決定輸入什麼、輸出什麼。」雖然本篇文章介紹的是文字生成和圖像生成,但其實像是語音、音樂、影片等創作,也都可以用類似的方式產生。
從以前開始,AI 就不只是AI 工程師的事。例如在生成式AI 的應用上,到底要讓電腦去學什麼、決定模型的輸入或輸出是什麼,人人都可以有自己的一些創意想法。而生成式AI 更有趣的地方則在於,即使是同一個模型,每個人又可以用不同創意、想法做出不同的應用。未來生成式AI 將在更多場合大展身手,不論讀者們想要做AI 工程師,還是想讓AI 對自己有更多的幫助,生成式AI 都是值得你好好學習的一項實用工具。
延伸閱讀
蔡炎龍,(2022)。我們的AI 模型和正確答案差多少?了解深度學習中的數學原理。科學月刊,629,42–47。
閱讀完整內容
本文摘錄自
封面故事一:揭密ChatGPT、Midjourney 生成式AI如何學習
科學月刊
7月號/2023 第643期
相關