輝達公告財報又給市場新的驚喜,更重要的是,輝達不但端出更高的展望,又加上近期微軟、英特爾、超微也同聲看好AI明年發展,台股AI的ASIC、伺服器、先進製程五檔新生力軍正式躍上檯面。
文/黃俊超
十一月FOMC會議維持利率不變,加上美國就業數據大幅降溫,以及十月消費者物價指數(CPI)低於市場預期等因素,都使投資人看好美國經濟已走緩到足以讓通膨降溫,且無衰退之虞,因此短線在預期聯準會(Fed)有望終止升息的樂觀情緒下,全球股市迎來強勁反彈,尤其對利率敏感的科技股也獲資金簇擁。
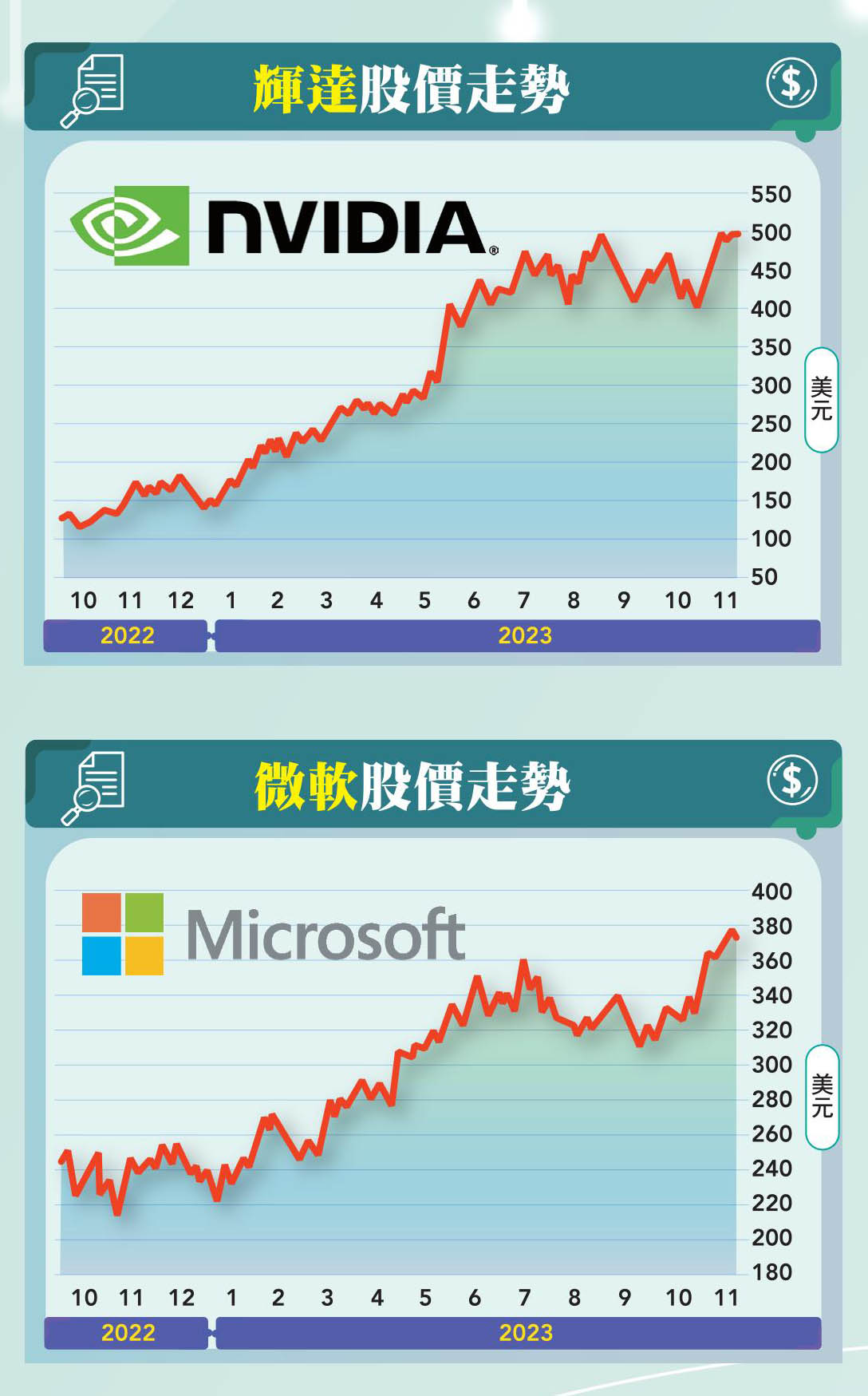
其中,美股七巨頭財報公告壓軸的輝達(Nvidia)在市場預期Q3財報將可望有好表現的帶動下,財報公告前夕股價就已突破八月大量高點、再創歷史新高。而公告後也確實再一次給市場驚喜,單季營收達一八一億美元,優於原先市場預期的一六二億美元,季增逾三成、年增逾兩倍,調整後每股盈餘四.○二美元,季增五成、年增近六倍;且財測展望也相當強勁,Q4營收預測中位數二○○億美元,遠高於一八○億美元的普遍預期,意即年增會繼續突破二○○%。
輝達Q3財報開出好成績
按業務表現來看,核心的資料中心收入年增近二八○%,達到一四五億美元,創下歷史新高,其中有一半是由亞馬遜等雲端服務供應商(CSP)所貢獻,另一半則來自消費者網路實體和其他大型公司。而對於市場關注的資料中心的營收是否可以一路成長至二五年,輝達高層也回應「Absolutely(絕對地)!」動能包括輝達日前宣布以H100晶片原型為基礎,推出的HGX H200,搭配最新H200 Tensor core GPU將會是第一款搭配HBM3E記憶體,系統將會在明年第二季出貨。
此外,輝達也宣布推出人工智慧代工服務(AI foundry service),為部署在Microsoft Azure上的企業和新創公司增強客製化生成式AI應用程式的開發和調整;簡言之,輝達將提供企業客製化AI服務。法人表示,因為每間公司都有自己的資料與技術,不希望向外採購,故此服務是借鏡台積電成功的晶圓代工模式,顯示輝達積極嘗試AI各項創新,將全方位滲透人工智慧。

不過,雖上季財報、本季財測輕鬆優於華爾街預期,但盤後股價仍跌逾一%,因為輝達財務長克萊斯(Colette Kress)表示,最近幾季,輝達受到限制出口的產品銷售額約占資料中心收入的二○到二五%,且對中國等國家的銷售預估將在第四季大幅下滑,但仍預期削減的幅度可以藉由其他地區的強勁成長來抵銷。儘管美國政府對半導體出口中國的政策不斷縮緊,繼去年美國政府發布對中晶片出口管制措施後,今年十月美國商務部再頒布新規,又把原先輝達為中企設計的降規版AI晶片A800、H800納入管制。
但根據外媒報導,輝達已再研發出針對中國市場的最新降規版晶片,包括GX H20、L20 PCIe和L2 PCIe,均基於H100改良而來,產品分別適用於雲端訓練、雲端推理以及邊緣推理,會把性能降到新規定的參數以下。而這已是一年多來輝達第二度被迫為中國客戶重新設計產品,且據悉,輝達已通知中國經銷商,三款新晶片符合美國規定,最快可能在年底前上市。
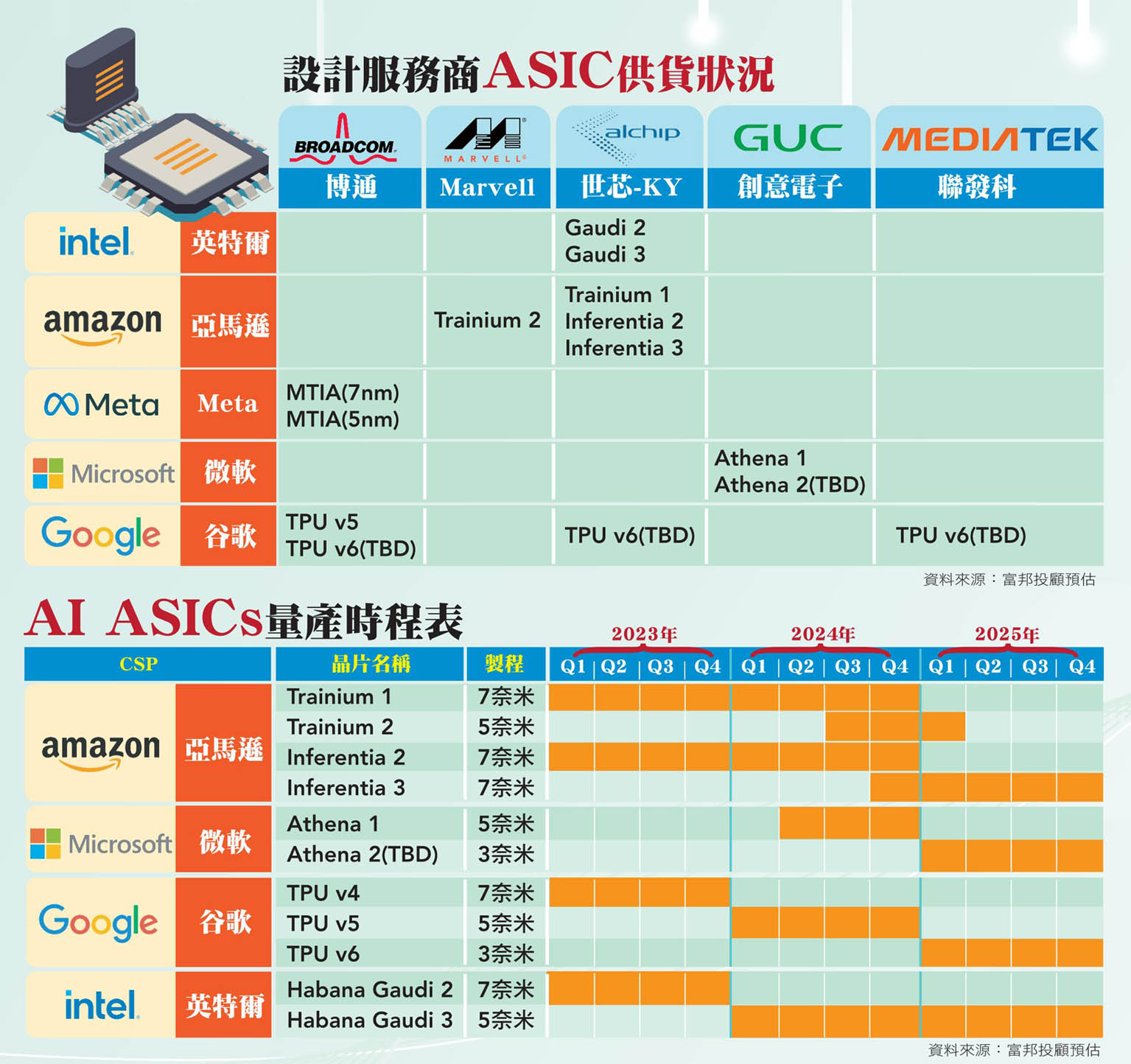
當前,輝達作為領頭羊持續引領AI產業,而各大雲端服務商如微軟、Google、亞馬遜等亦皆不斷加大AI投資力道,推升AI伺服器需求上揚。根據研究機構TrendForce估算,今年AI伺服器(包含搭載GPU、FPGA、ASIC等)出貨量逾一二○萬台,年增將達三七.七%,占整體伺服器出貨量達九%;明年將再成長逾三八%,AI伺服器占比將逾十二%。而除了輝達與超微(AMD)的GPU解決方案不斷攀升外,AI應用還有許多基礎建設像是AI推論、客製化AI晶片、特定領域應用等需求,加上目前通用GPU市售價格昂貴,且供不應求,因此CSP業者擴大自研ASIC晶片的趨勢也成為近期市場熱議的焦點。
AI晶片吹自研風
其中,Google算是最早投入ASIC晶片研發的巨頭,自一五年以來,Google就於內部使用TPU來加速AI、機器學習和深度學習等任務。公司表示,最新的第四代TPU將深度學習效能提升十倍以上,並且降低二○倍以上的二氧化碳排量;更強調與輝達的A100晶片相比,TPU v4加速器在相同建置規模下的算力表現約提升一.七倍,能耗部分則降低一.九倍。且除用於內部外,也向外部合作夥伴提供服務,如AI新創公司Midjourney已經使用TPU v4來訓練文字生成圖片模型。
而微軟則是新加入者,其日前宣布推出兩款自研AI晶片,包括專為雲端資料中心設計能夠降低功耗及成本的Arm架構處理器Azure Cobalt,以及專為AI運算設計及首款雅典娜計畫(Project Athena)加速晶片Azure Maia。業界人士分析,微軟選擇自行研發客製化AI晶片的策略,與對外採購GPU相較,在維持同等AI算力情況下,可大幅降低建置成本。
目前微軟在AI運算服務市場可以說已打下穩固基礎,Maia晶片推出,說明微軟會持續朝向自有AI晶片研發之路發展。此外,微軟明年也將提供客戶採用輝達H200 GPU和AMD MI300X GPU的虛擬機器(VMs)服務,兩款晶片都能用於執行AI任務。
CSP廠ASIC蓄勢待發
亞馬遜近年推出兩款AI、ML專用晶片Inferentia與Trainium。Inferentia是推論專用晶片,在處理AI運算任務時,能比一般GPU架構傳輸量更高、延遲更低,但卻能同時降低運算成本;Trainium則為訓練專用晶片,能優化圖片分類、翻譯、語音識別、推薦引擎等深度學習訓練任務,並與AWS上的AI/ML開發環境SageMaker搭配有著更出色的運算表現。
另外,還包括Meta的自研MTIA晶片,以及特斯拉開發Dojo 1、英特爾開發ASIC加速器Gaudi等,都可見ASIC正式成為半導體一大新賽道。ASIC之所以在AI應用逐漸嶄露頭角,簡單來說,ASIC為專門處理相對應的AI運算任務所誕生,在設計初期就已限定將使用何種AI模型,其優勢為能夠開發出符合自身需求的晶片,且因是客製處理在效能表現上會優於通用GPU,在生產成本、專用度、功耗、算力皆優於GPU;然而當需求出現變化時或是運算上、任務上的改變,該晶片將有可能失去所有作用,無法進行支援,且ASIC設計時間較長,通常需要二到三年,因此GPU主要用於雲端的訓練、推論功能,而ASIC多用於雲端或裝置端、邊緣端的推論AI晶片。
對此,輝達執行長黃仁勳先前就提及來自客製化IC與CSP業者的競爭,但其強調,輝達不僅是晶片供應商,也提供軟體、函式庫(library)與演算法等整體運算架構,給予客戶最低成本(TCO)的解決方案;同時輝達也正不斷推陳出新,以拉近與ASIC間的不足。綜上來看,在未來擁有極大成長潛力的生成式AI市場中,究竟輝達能否持續稱霸市場?亦或是CSP業者有望抗衡?預期將會是資本市場一大關注重點。
閱讀完整內容
本文摘錄自
精選5檔 Nvidia財報紅利股
先探投資週刊
2023/11月 第2275期
相關