各家雲端大廠為求降低整體成本,配合自家生態軟體與應用而開發ASIC,這將是繼通用GPU之後,AI的新戰場誕生了!
文/周佳蓉
在算力多元的時代,人工智慧(AI)已然成為科技業下一個十年的投資顯學,生成式AI席捲全球,雖然相關個股如輝達(Nvidia)、超微(AMD)等經過一年多的瘋狂炒作,GPU需求仍不斷攀升,AI基礎設施還有許多層面例如推論AI、客製化晶片(ASIC)都還處在起點階段,後面巨大的應用商機更獲得科技巨頭的高度重視,這也能解釋為何Meta創辦人祖克柏,會願意斥資鉅額大量買輝達三五萬台H100GPU,Meta計畫在年底前建置更多AI伺服器,加計其他的GPU在內運算能力相當於六○萬台H100的等效運算,光以H100售價在二.五萬~四萬美元之間統計,支出也至少逾百億美元。

▲在規模及成本考量下,全球CSP業者對自研晶片需求水漲船高。達志
然而GPU的市場需求太大而供給有限,大型企業除了成本、供給問題,最終能否創造因應自身環境、符合高度客製化需求的AI晶片,也是企業的考量重點所在,因此,舉凡Amazon、Google、微軟、Meta等也紛紛切入自研晶片領域,更以ASIC創造差異性,優化自家產品,有別於通用GPU在運算任務中表現出色,未來當資料中心的任務從訓練階段走到了推理階段,則是ASIC大展鴻圖的時刻。外資大摩更預估,ASIC晶片將在未來幾年比通用型GPU帶給台積電更多進帳,也就是說,ASIC長遠的發展性可能更值得期待。
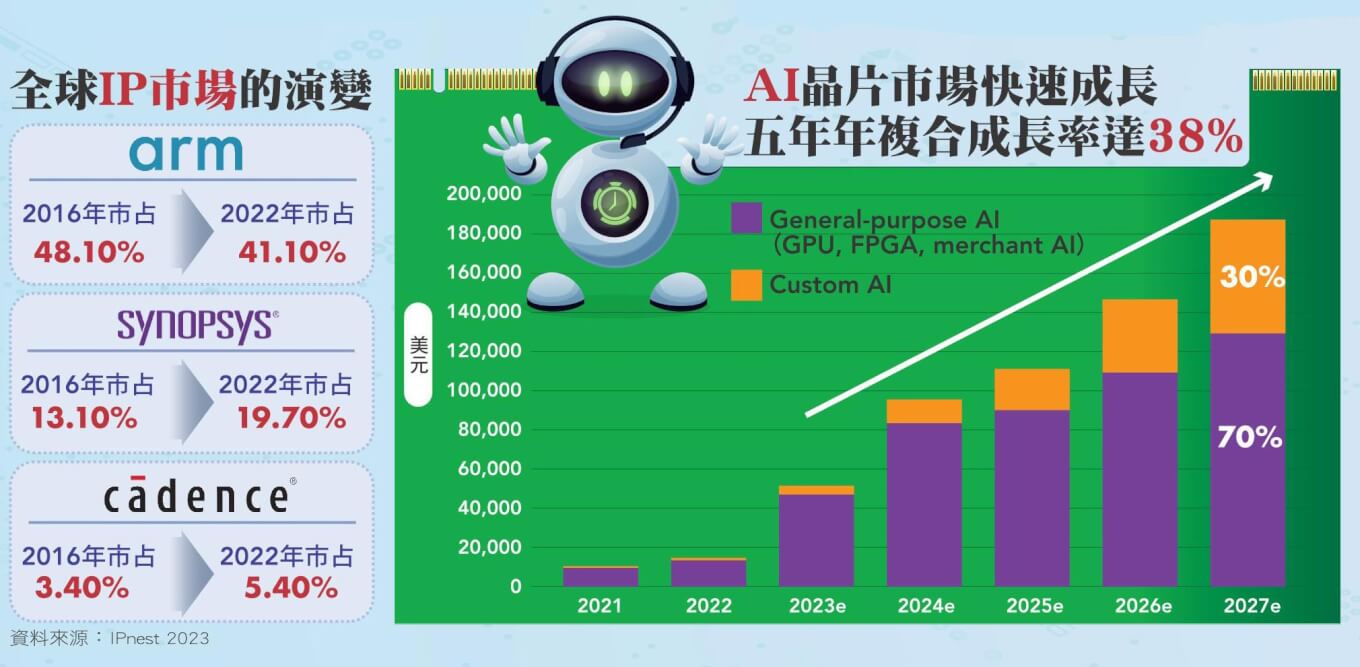
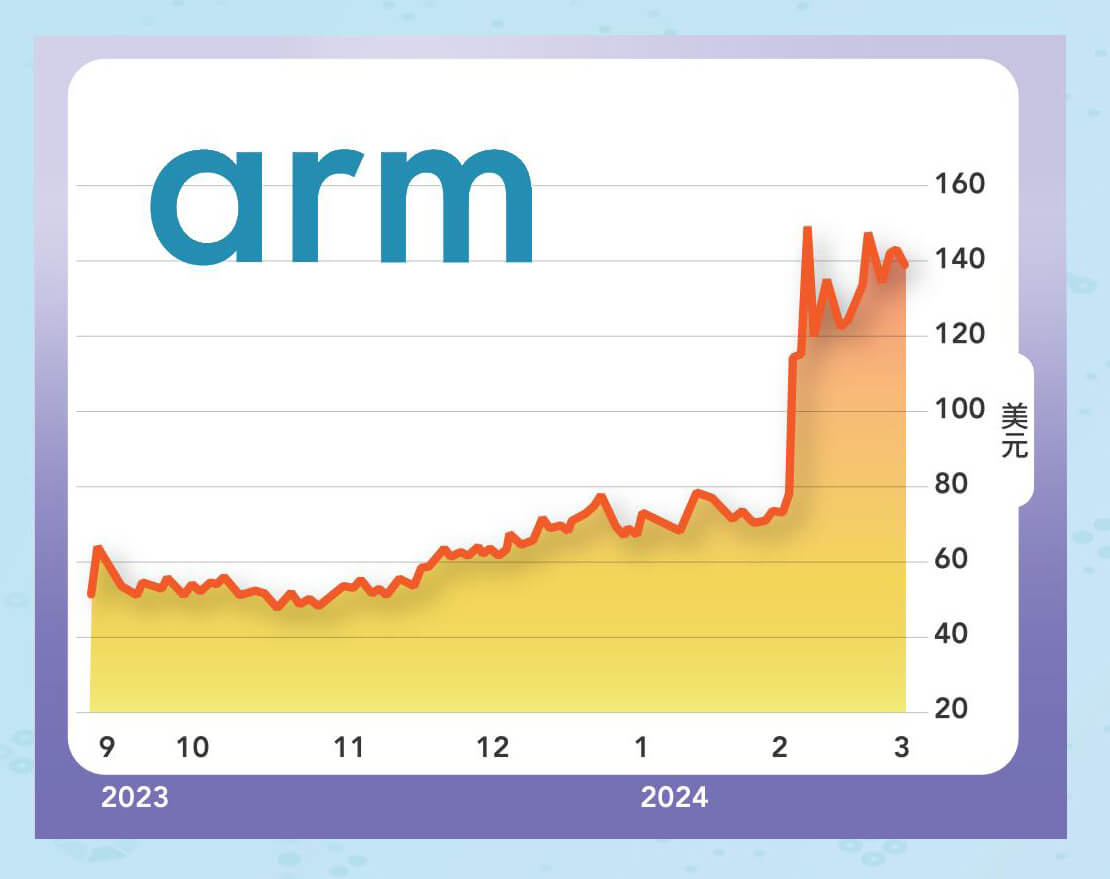
ARM的業務長期聚焦處理器的核心矽智財,以及對晶片公司提供授權,位於半導體產業的最前端,除了收取矽智財的前期授權費,也根據晶片售價,按比例收取版稅(royalty),ARM在手機處理器馳騁多年,一直保有超過九成的市占率,並且持續進軍雲端運算、汽車、物聯網等領域,而ARM架構的伺服器也自二○○九年發展至今超過十五年,成為X86處理器以外的第二選擇,不過隨著行動裝置和消費電子市場趨於飽和,ARM在全球IP市場占有率甚至從一六年的四八%下滑至二二年的四一%,也不得不開始尋找新的業務突破。
ARM結盟打團體戰
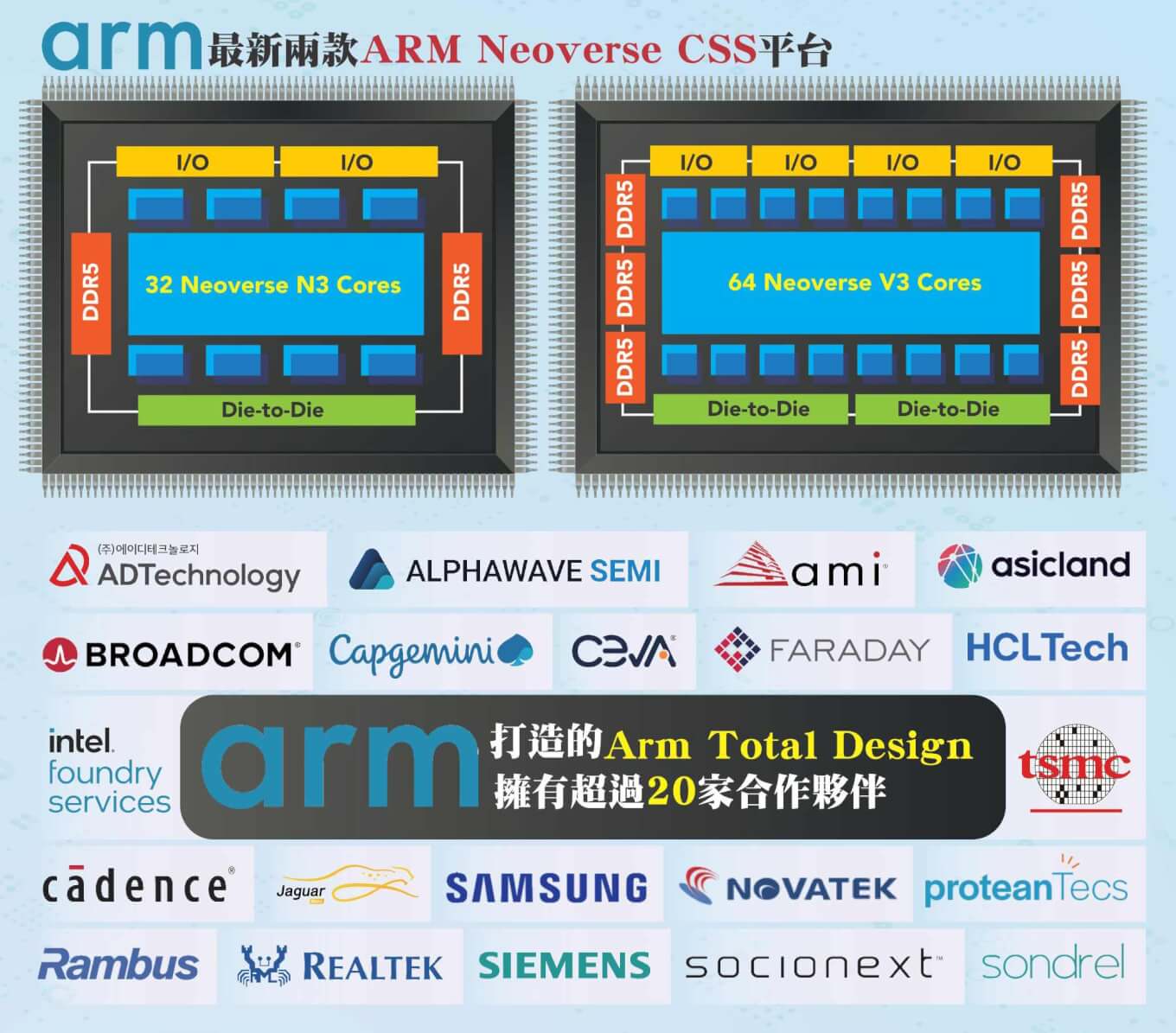
ASIC是ARM下一階段相當看重的市場,去年下半年ARM發表了NeoverseCSS運算子系統,CSSN2便是首款專注於SoC和系統級創新的平台,採用先進的五奈米製程技術,適用於5G到雲端運算、機器學習的各類應用,已採用的業者為微軟用於Cobalt晶片,同時為開發專用晶片的客戶降低成本、縮短上市時程,今年二月再推陳出新兩款CSSV3、CSSN3平台,分別為插槽效能五○%的提升、每瓦效能提升二○%,V3在單晶片上最多可擴展至一二八核,並支持最新的高速記憶體和I/O標準;N2則更適應於電信、網路和資料處理單元、雲端配置等重視能源效率的領域,兩平台皆以第三代NeoverseIP為基礎建構而成,ARM也以此改變以往授權單個IP為主的商業模式,能將多個IP整合後打包販售。
ARM更集結各界力量打造全面設計(TotalDesign)生態系版圖,納入台積電(2330)、英特爾(Intel)、三星(Samsung)晶圓代工大廠,還吸引益華電腦(Cadence)、新思科技(Synopsys)、博通(Broadcom)、Rambus(RMBS.US)等EDA、IP業者加入,台廠方面除了智原(3035)率先成為首波IC設計供應商,瑞昱(2379)、聯詠(3034)則在半年內成為新加入的生力軍,如今生態系全員已超過二○家公司。
其中,IP市占率僅次於ARM的新思科技,更在EDA全球市占中領先第一,工程師可透過EDA,將晶片的電路設計、性能分析等整個IC版圖交由電腦自動處理,不僅如此,新思科技也與微軟就生成式AI方面展開合作,整合EDA工具推出Synopsys.AICopilot,能加速晶片工程師設計晶片的時間,預期未來將吸引更多客戶。
另外,高頻寬記憶體(HBM)因擁有更高的頻寬和較低的耗能,新一代的HBM3頻寬更是DDR5的十五倍,不論是搭載GPU或ASIC形式的AI伺服器,都陸續採用以HBM為主流的記憶體解決方案。Rambus在專利/架構授權業務占比較高,主要有基礎IP授權、半導體IP授權和晶片業務,記憶體IP中包括DDR、LPDDR、HBM甚至是CXL控制器IP,面向資料中心和邊緣運算市場可滿足不同ASIC應用需求,Rambus去年底因應AI趨勢推出基於HBM3的內存控制器IP,可提供最高達九.六Gbps的傳輸速率,相比輝達H100所採用的HBM3的六.四Gbps,傳輸速率更大勝一.五倍。
近來,國際大廠將各家IP資源整併發展AI已是趨勢所向,英特爾二月宣布,將提供專為AI的系統級晶圓代工服務,就提到已將ARM、Synopsys、Cadence、Siemens、Ansys、Lorentz、Keysight等廠商都納入生態系之中,並適用於英特爾十八A製程和先進封裝的工具、設計流程和IP,打造共贏的局面。
誰會接下Google TPU v6訂單?
隨著ASIC蓬勃發展,四大CSP業者皆積極布局下,博通(Broadcom)和Marvell(MRVL.US)無疑扮演著領導者角色。Google一直是博通的重要客戶,也專門對Google開源深度學習框架TensorFlow和Jax框架,開發出高度優化的AI加速器(TPU),TPU的運算效能在特定AI工作負載下,超越傳統GPU,這種深度合作關係,使博通在AIASIC市場中占有一席之地,關於台廠方面也有消息傳出,聯發科(2454)或世芯KY(3661)可望接獲GoogleTPUv6訂單,二五年以台積電三奈米量產。
另一方面,Marvell也是AI加速器晶片的重要供應商,Marvell AI系列產品已成功打入雲端資料中心、智慧城市、智慧製造等領域,也與微軟的雲端服務Azure有著緊密合作,憑藉著過去累積的豐富客製化ASIC模型經驗,已累積生產了超過二千套客製化ASIC。隨著AI運算需求持續激增,Marvell有望繼續擴大在ASIC市場的版圖,最終,誰能掌握關鍵技術並贏得重要客戶,將決定未來在ASIC戰場的走向。
閱讀完整內容
本文摘錄自
ASIC全面Re-rating AI賽道的下一個明星…
先探投資週刊
2024/3月 第2290期
相關