掌握趨勢 讓語言訓練不只英文、簡中
ChatGPT 一夕爆紅,讓各國大型語言模型軍備戰開打,中國有文心一言、法國有Bloom,台灣也跟進趨勢,企業與國家單位合作,推出台版GPT,要把繁中模型愈養愈大。
文—黃亦筠 攝影—王建棟

▲大型語言模型,成為各國在這波AI大賽中的競爭力核心。
「終於可以把繁體中文的大型語言模型捐贈出來了,目前出到十億參數等級,雖然離千億等級尚遠,不過已經可以穩定輸出算是有意義的胡謅了,」二月底,聯發科的前瞻研究單位,聯發創新基地總監許大山,在自己臉書突如其來地宣布。
爆紅的ChatGPT帶動大型語言模型熱潮,Google、Meta紛紛公開自家版本的類似模型。不少業者預言,未來人類生活的諸多科技應用,背後將由少數幾個美國企業的大型語言模型驅動,類似雲端服務由亞馬遜AWS、微軟Azure、Google Cloud三家寡佔的狀況,但影響將更深遠。
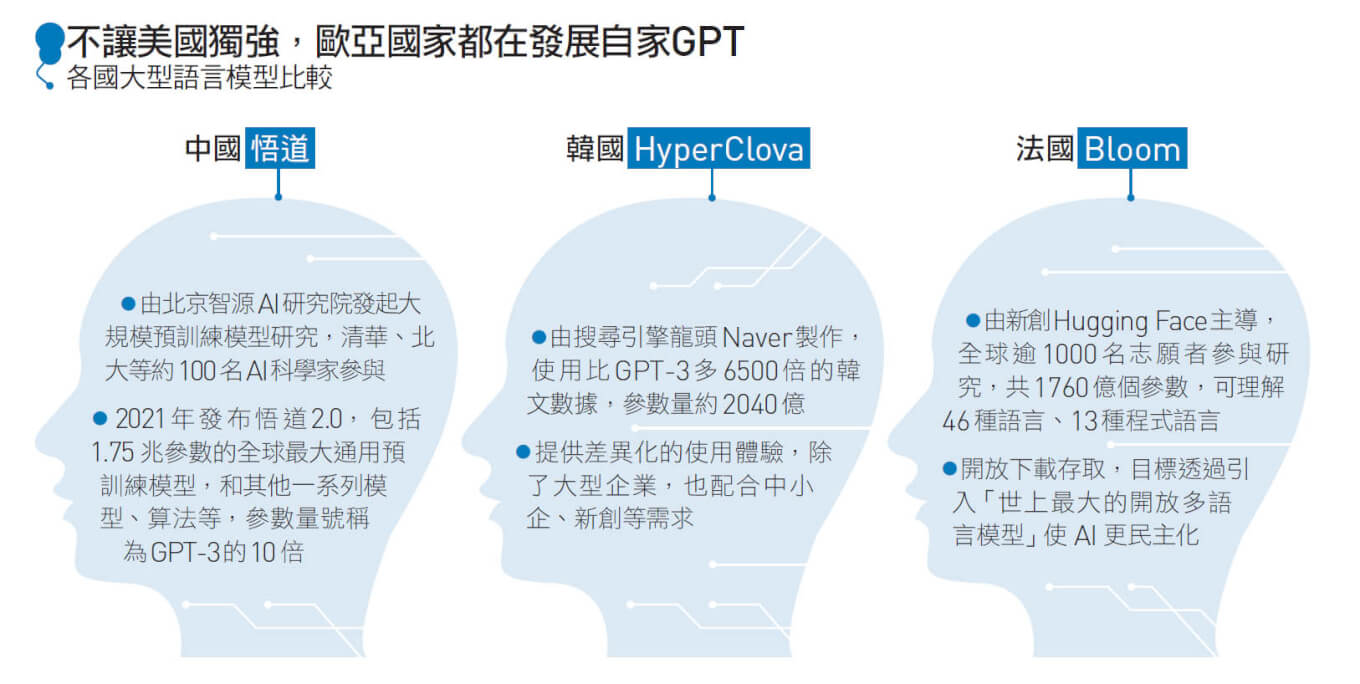
一夕間,全球大型語言模型軍備戰開打,中國有「悟道」及百度的「文心一言」,法國有「Bloom」,韓國有「Hyper Clova」……,台灣也終於發表全球第一個繁體中文AI語言模型,並免費提供使用,二月公布至今,開放給AI開發者使用,累計超過三千四百次下載。
這個被外界比喻為「台版GPT」的繁中版語言模型,正是由許大山領軍的聯發創新基地,結合中央研究院詞庫小組以及國家教育研究院三方,在法國的開源語言模型Bloom上開發的。
「聯發科」主力研究生成式AI
過去大型語言模型多以英文為主要優化,就連中文的資料訓練,也是用簡體資料較多,繁體中文的語言模型非常不足。目前OpenAI也只開放API架接,對模型沒有任何主控權。
「主動權沒有在我們這些繁體中文使用者手上,就是有種無力感,」許大山表示。
許大山曾是美國高通3G時代的蜂巢式網路演算法負責人,也曾在台大電機系任教,他在二○一一年加入聯發科。
在他的帶領下,聯發創新基地主要專注在AI研究,最早先在英國劍橋設據點,就近網羅在地人才,劍橋是英國AI重鎮,不只三星在這裡設AI中心,連輝達(Nvidia)也將英國最強超級電腦設在此處。
兩年前,長年待在劍橋的許大山,感受到須掌握生成式AI的未來發展,他開始將人力調至生成式AI研究,直到OpenAI推出GPT-3,他覺得時候到了。
「AI對productivity(生產率)的提升,層次完全不一樣,那是一個跳躍,」許大山說。當時聯發創新基地內二十多個研究員,一半都放到生成式AI的領域。
去年五月,聯發創新基地和中研院詞庫小組接上,預備發展一套繁體中文版大型語言模型。
「國教院」餵食高質量繁中資料
其實早在二○一九年,中研院詞庫小組就曾用Google推出的BERT語言模型,和OpenAI的GPT-2,做過繁中版模型,但受限於資料量不足,與主流的大型語言模型差距很大。
中研院於是帶進國家教育研究院,國教院累積大量繁體中文出版品,以全都是高質量的繁中資料供模型訓練,再加上從新聞網站、網路平台、論文庫等蒐集來的繁中資料,就放上開源的Bloom模型訓練與優化。
有了包括國教院的語料,讓原本的繁中模型資料量多一千倍。許大山團隊也開放外界下載這套模型,可用於類似ChatGPT的問答、文字編修、文案生成等。
目前這套繁中語言模型還小,之前是在聯發科自家資料中心訓練,但持續訓練讓模型愈大,就需要更大量的算力(HashRate)。
「只要有算力,搭配我們已經有的基礎,就可以繼續往前面走,」許大山說。
「台智雲」擁有本土最強算力
而台灣最強的算力資源,就是國家網路與計算中心的超級電腦「台灣杉二號」。許大山坦言,正接洽國網中心,尋求合作機會。
「如果二○一七年沒有扎下這顆火種,台灣現在很難跟上這一波ChatGPT帶起的生成式AI熱潮,」坐在華碩AI雲創園區大樓內,台智雲總經理吳漢章說。台智雲是台灣杉二號的維運單位。
二月底,台智雲剛公開展示在台灣杉二號上運行Bloom,證明有能力運算與GPT-3同等級的一七六○億個參數的大型語言模型,一炮打響知名度。
「AI的戰爭,在系統算力。有系統算力,就有機會延伸產業供應鏈的關係,」吳漢章強調。
位於新竹的台灣杉二號,是二○一七年透過國科會前瞻計劃,四年投入五十億,由廣達、華碩、台灣大哥大打造。
一八年全球五百大超級電腦排行,台灣杉二號每秒九千兆次浮點運算的速度,名列前二十強。
前瞻計劃結束後,二二年由華碩班底為主的台智雲承接。華碩雲端總經理吳漢章,也接任台智雲總經理。
華碩曾發展服務型機器人Zenbo,當時內部就有一組發展自然語言處理(NLP)團隊,後來承接台智雲,對語言模型不陌生。
台智雲原本預設三個領域拓展業務,分別是基因分析、精準醫療、數位雙生,沒想到ChatGPT突然出現,一下帶起大型語言模型的算力需求。
台智雲於是設定了商業模式,就是當「算力的提供者」,類似台積電提供產能服務,讓IC設計公司可以專心做晶片設計。
然而,科技圈一直有一股質疑的聲音。一名伺服器大廠高層就向《天下》直言,再怎麼砸錢,台灣從政府到民間,都不可能拿出Google、Meta等級的經費,養一個大型語言模型和超級電腦。
面對質疑,行政院科技政委吳政忠倒是持不同看法,他正召集專家,希望年底能產出一個繁中共用模型。
原因就在於,他認為全球民主與極權出現分割趨勢,面對ChatGPT餵入大量簡中語料,中國推簡體中文版悟道、文心一言,可能出現迎合中國民眾的論述「偏見」。
吳政忠表示,台灣必須有自己的可信賴AI對話引擎。

▲「未來,要讓台灣的算力輸出海外,」台智雲總經理吳漢章有很堅定的信念。
然而基礎模型訓練需要龐大的算力資源,大量資金成本不是一般企業能輕易投入。
「這需要大型企業出來領軍,建立一個大型基礎模型的開發環境或生態系,」台灣大學資工系教授鄭文煌,在三月鴻海研究院舉辦的人工智慧論壇上直言。
吳漢章則認為,台灣杉二號能輸出台灣的算力服務。
當前全球超級電腦前一百名當中,能夠用作商業營運的不超過二十五台,其中有七台是石油公司自有自用,另外三台是輝達研發自用,四台是微軟用來服務OpenAI,另外五台屬於俄羅斯網路公司Yandex。
「但你敢用俄羅斯的超級電腦嗎?他們和我們已經是兩個世界,至少軍事、國防類的需求不敢用,」吳漢章說。
還有兩台在韓國人手上,分別在三星以及韓國電信SKT。「放眼亞洲,就三台能做商業運作,兩台在韓國,另外一台就在台灣,」吳漢章說。
就如同台積的客戶不只有台灣IC設計公司,台智雲的算力服務,也是放眼海外市場。最近就有海外客戶找上台智雲,希望能運用台杉二號的算力跑基因定序。
台智雲已規劃擴增算力,「未來,要讓台灣的算力輸出海外,」吳漢章說。

▲聯發創新基地總監許大山坦言,目前國外大型語言模型,主動權不在繁中使用者手上,「有種無力感。」
本文摘錄自
全球首個繁體中文模型國家隊打造「台版GPT」
天下雜誌
2023/4月 第770期
相關