
▲張凱崴
台灣大學資訊工程系碩士、美國伊利諾大學(UIUC)電腦科學博士。美國加州大學洛杉磯分校(UCLA)電腦科學系助理教授,研究領域包括人工智慧、機器學習、自然語言處理。2021年獲得史隆研究獎(Sloan Research Fellowship),研究團隊開發的運算方法,使人類語言處理的程序更有效率、更多元,同時兼具公平性。(圖片提供/ Shutterstock)
AI局限1:資料寬廣度不足時, 就會複製人類偏見
張凱崴認為,電腦在學習的時候,是依賴「彙整數據資料」來判斷,並沒有真正思考,如果資料來源太狹隘、不夠多元,資料寬廣度不足,電腦判斷就會出現偏差,「你跟電腦講清楚input(輸入)、output(輸出),提供足夠的數據資料,它可以對應、學得很好,但還有很多面向AI做不到。」
舉例來說,亞馬遜(Amazon)2014年推出智慧音箱(Amazon Echo),使用者口頭下指令給語音助理Alexa就能放音樂、查資訊。然而,有些人口音較罕見,或是用字較特殊,智慧音箱的資料庫沒有「不同口音」「不同用詞」的檔案,就可能失靈,這是當前AI的其中一大問題。
張凱崴進一步解釋,AI另一項挑戰是,它無法清楚分辨「不曾出現」與「不能出現」(無法出現)之間的區別,只是從資料統計出要學的東西,無法像人類一樣進行邏輯思辨。
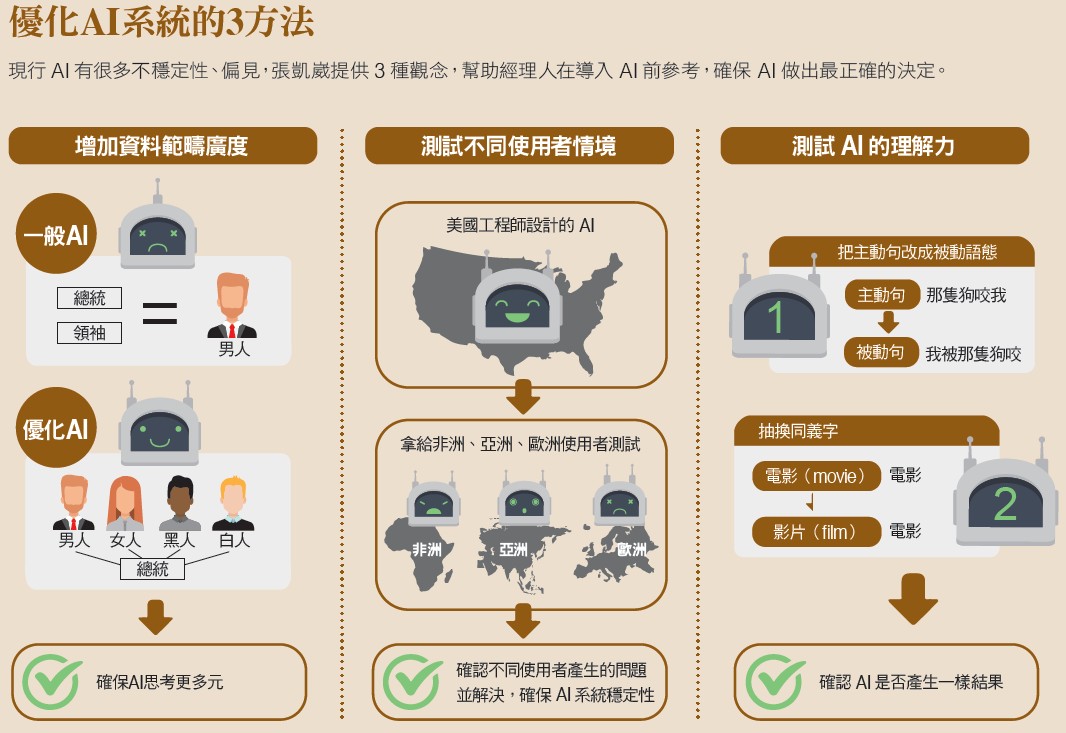
AI的運作方式,第一步是輸入資料,第二步是分析,但這過程容易出現偏見。例如電腦在理解「總統」這個字,會去看四周有什麼字詞,來學習總統這個詞,由於許多總統都是男性,電腦就會「覺得」總統是男性。
這也是為什麼,如果讓AI學習,在它的認知裡,女性「不可能」當美國總統(因為沒有資料紀錄)。「你可以跟人類說,任何職業、性別都是平等的,但對電腦來講,這很困難,」張凱崴說明,一旦資料的寬廣度受限,電腦就容易產生偏見。 就像在自然語言處理(Natural Language Processing,讓電腦把輸入的語言變成有意義的符號)領域,張凱崴說明,AI需要知道代名詞指的是「哪個名詞」,才能運算下去。但如果資料受限,使用男性的「他」,電腦可能判斷這個代名詞是指總統、總理、執行長;但換成女性的「她」,由於數據不足,電腦就會混亂,出現系統性誤差。


他再舉一例,美國人工智慧研究組織OpenAI提出「生成式預先訓練」系統(GPT,Generative Pre-training),推出到GPT3版本,屬於書寫類AI,電腦能夠揣測人們說完上一句話,下一句可能會講的句子,自動完成後半段。
好比有人上一句寫下「我正在和教授聊天」,系統可能推導出「我們在研究室討論學術問題」,因為電腦藉由蒐集來的語料資料中判讀出「教授」和「學術」具高度相關。但研究也顯示,GPT2(前一代版本)系統也從資料中學習到許多偏見,像是如果句子前半談論白人男性,系統傾向產生正面評價;如果句子前半是黑人女性,系統竟會產生負面句子。對企業來說,許多組織接觸AI,想讓它們取代部分工作,首先需要留意資料的廣度、多元性,才能減少電腦犯錯的機會。
「其實,現在的AI就像一台原型飛機,還缺乏穩定性。」張凱崴說,現行的AI就好比萊特兄弟(Wright brothers)剛發明飛機,看似可以做很多有趣的事,但「可以飛」跟「飛得很好」,有一大段落差。
紐西蘭的簽證系統曾鬧出笑話。人們上傳簽證照片,AI掃描後,確認是不是本人,但當時系統沒有估算到某些亞洲人眼睛比較小,一名亞裔男子被判定「沒有張開眼睛」,因此照片無效。
張凱崴說,在這個例子中,凸顯出AI的穩定性不足,「系統沒有考慮到不同人種的差異,很死板地認為你眼睛沒張開。」所謂的缺乏穩定性,指的是AI沒辦法在相同條件下,每次都做出正確決策,這也是使用AI時,須留意的第二個挑戰。
他再舉例,許多模型可以準確分析,一則影評對電影的評價是正面或負面。然而研究顯示,有時只要將影評中一些字換成同義詞,例如把電影(movie)換成影片(film),或改寫句子,即使意思並未改變,系統卻把原本判斷為正面的影評標註成負面。這顯示AI系統還未真正了解語言的含義。在設計這些程式時,人們必須注意到AI可能有局限,設定的資料範圍要更完整,考慮這些因素,就能減少偏見、落差,進而加強穩定性。
餵指令給AI要多元化, 嘗試「換句話說」、刻意混淆
經理人雖然不一定具備AI方面的專業知識,但只要掌握觀念,再透過AI領域專才協助,也能優化系統。張凱崴指出,最直接的方法是,設計AI模型時,要把來源群組不同的資料分門別類測試,在測試階段讓群體多元化,並確保不同特色的使用者,用起來都沒有問題。
舉例來說,一套A系統擁有來自各地的使用者,如果設計者是台北人,設計系統的思維容易以台北生活為主,很可能因為當地習慣不同,導致花蓮使用者操作不順。
另一個方法,則是用不同的「語意」,去測試AI有沒有徹底學會一個概念。例如,有一套餐廳評鑑的AI系統,只要蒐集、整理使用者意見,就能判斷每個顧客對於餐廳的評比是高分或低分。那麼要如何確認這套系統的穩定性?張凱崴建議,可以利用「抽換詞面」的方法。
比如,把詞彙換成同義字,再看AI是否能運算出相同結果,「你可能會發現,原本評比結果是食物很美味,但如果美味換成比較困難的詞,AI就會分不出這則評比是好是壞。」因此在訓練模型時,可以將詞彙隨機抽換成同義詞,增加AI的詞彙量。
第三種方式更進階:改變句型、重寫句子。張凱崴指出,同樣一句話,如果換成不同說法,電腦可能判讀錯誤,將「因為發生A事件,所以導致B事件」,改寫成「B事件發生了,是因為A事件的緣故」,明明兩句話意思一樣,但AI很可能因為穩定性不足,搞混兩者的差別。如果要鞏固AI的穩定性,可以使用自動改寫的方式,增加資料的多樣性。
張凱崴表示,經過這些測試,讓AI接受更多元化的訓練,得到更廣的學習範圍,往後碰到同義詞、相似資訊,才能有效判讀。
張凱崴總結,AI還在快速發展,或許可以創造更多工作機會、新的職位,但現行階段,它只是輔助角色。AI並非魔術盒子,使用它就一定有更好結果,人們還是要保持高度耐心,先認識它的缺陷,才能在技術更迭下,發揮出最好的結果。
閱讀完整內容



